En energía, casi todos los dolores operativos se ven iguales desde lejos: “faltan datos”, “el reporte no cuadra”, “la demanda salió rara”, “la boleta viene distinta”, “en la planta dicen una cosa y finanzas otra”.
Pero cuando te metes a la cocina, el problema real suele ser más simple (y más incómodo): tratamos el dato energético como si tuviera una sola velocidad. Como si todo fuera “capturar → subir → graficar”.
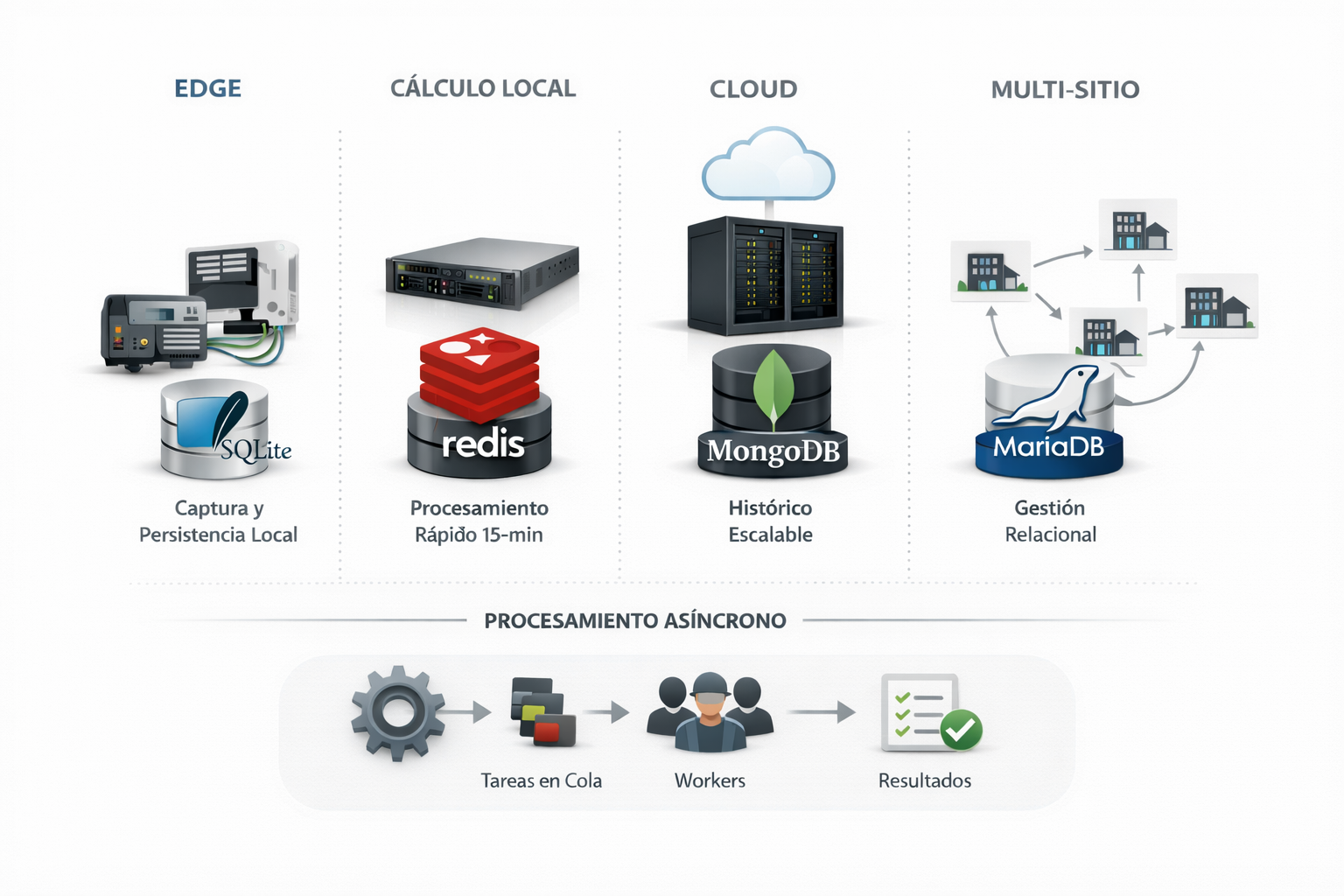
En la práctica, el dato energético vive en cuatro velocidades distintas, y cada una exige decisiones técnicas diferentes. No por moda, sino por supervivencia operativa:
edge → cálculo local → cloud → operación multi-sitio
A continuación, un recorrido técnico (pero aterrizado) de cómo estas velocidades se traducen en arquitectura con nombre y apellido: SQLite3, Redis, MongoDB, MariaDB y Celery, conectando MetricFlowOne con MetricView360.
Velocidad 1: Edge — el dato nace en un mundo imperfecto
El edge no es “una mini nube”. Es un ambiente hostil: reinicios, cortes eléctricos, redes ruidosas, latencias raras, gateways con recursos limitados, y conectividad que no puedes dar por sentada.
En ese contexto, la primera regla de diseño es brutalmente práctica:
Primero persiste. Después transmites.
Ahí es donde SQLite3 se vuelve una decisión lógica: una base embebida, liviana, sin dependencia de un servidor externo, ideal para persistir localmente mediciones y eventos. En una operación offline-first, SQLite funciona como la “caja negra” del sistema: si todo falla (internet, VPN, broker, API), el dato igual queda guardado.
Eso permite que MetricFlowOne cumpla su propósito: transformar lecturas crudas en datos confiables, continuos y trazables, incluso sin internet.
Qué resuelve en la práctica (no en teoría):
-
Evita huecos de datos por “caídas momentáneas” que terminan siendo horas.
-
Permite reintentos ordenados de sincronización.
-
Deja evidencia temporal de “qué se leyó, cuándo, y con qué estado”.
Criterio que suele faltar: en edge, no gana “la base más escalable”. Gana la base que no depende de nadie más para funcionar.
Velocidad 2: Cálculo local — 15 minutos no es un detalle, es un contrato
En energía, el intervalo (por ejemplo, base 15 minutos) no es un número arbitrario. Es un contrato operativo: es cómo se construye la continuidad, cómo se comparan períodos, cómo se detectan anomalías, cómo se concilia.
Pero si intentas hacer todo el cálculo encima del almacenamiento duradero, aparecen dos fricciones:
-
castigas el disco (sobre todo en hardware de borde),
-
mezclas responsabilidades: persistir vs calcular.
Ahí entra Redis como capa de cálculo rápido y caching: mantener estructuras en memoria para agregaciones por ventana, acumulados, estados de “última lectura”, y resultados intermedios. No es “otra base por capricho”; es separar dos trabajos que se pelean por recursos:
-
SQLite3: durabilidad + historial local
-
Redis: velocidad + cálculos por ventana (15-min) + cache de resultados
Este desacoplamiento suele mejorar 3 cosas:
-
latencia de cálculos (se siente en tableros locales o diagnósticos),
-
estabilidad bajo carga,
-
claridad al depurar: cuando algo falla, sabes si falló persistencia o cálculo.
Regla simple para recordar:
Persistencia y cálculo no deberían competir por el mismo motor, especialmente en edge.
Velocidad 3: Cloud — cuando el histórico deja de ser “un archivo” y pasa a ser infraestructura
Cuando pasas del “sitio” al “parque” (más medidores, más días, más granularidad), el problema cambia de naturaleza. Ya no estás discutiendo si guardas o no guardas: estás discutiendo cómo ingieres, particionas, consultas por rango temporal y retienes.
Es el punto donde una base orientada a documentos / series temporales como MongoDB puede tener sentido para el histórico masivo: modelar mediciones como documentos (o colecciones time-series) te permite escalar la ingesta y el acceso a grandes volúmenes sin forzar joins para cada lectura.
Si tu objetivo es soportar miles de millones de medidas, el foco es:
-
escritura sostenida (ingesta),
-
consultas por tiempo (rangos),
-
y diseño de índices/particiones acorde al patrón real de lectura.
En esta velocidad, el “dato energético” deja de ser un CSV elegante y se vuelve un flujo. Y el cloud tiene que absorberlo sin volverse frágil.
Velocidad 4: Operación multi-sitio — lo difícil no es almacenar, es convivir
Multi-sitio no es “más datos”. Es más realidad: sucursales, clientes, instalaciones, permisos, jerarquías, configuraciones distintas, calendarios distintos, y reglas que no puedes mezclar.
Ahí una base relacional como MariaDB aporta algo que suele subestimarse: estructura para la convivencia.
-
entidades claras (clientes, sedes, medidores, contratos, roles),
-
integridad referencial,
-
transacciones para cambios críticos,
-
y un modelo consistente para operar un sistema multi-cliente / multi-sitio.
La idea no es “relacional vs NoSQL” como debate religioso. Es reconocer que:
-
el histórico de mediciones puede vivir cómodo en un modelo orientado a series/documentos,
-
pero la operación (quién ve qué, qué pertenece a quién, cómo se configuran y auditan cambios) necesita una columna vertebral relacional.
Criterio de arquitectura:
El multi-sitio se rompe más por gobernanza que por storage.
La pieza que conecta las 4 velocidades: Celery (y la diferencia entre web y procesamiento)
Hasta aquí, hay una trampa: aunque tengas las bases correctas, el sistema puede seguir colapsando si todo ocurre “en el request”.
Cuando la plataforma crece, aparecen procesos que son pesados o impredecibles:
-
recalcular agregaciones 15-min por corrección tardía,
-
re-sincronizar períodos completos (backfill),
-
normalizar y validar lotes,
-
generar reportes,
-
reintentar envíos con lógica y trazabilidad.
Ahí Celery cambia el juego: transforma un sistema web en un sistema de procesamiento masivo asíncrono, con colas, workers, reintentos y programación. No es “hacerlo async por moda”. Es hacer que la plataforma pueda respirar bajo carga y manejar fallos como parte normal de la operación.
En términos prácticos, Celery te permite que el sistema sea:
-
más resiliente (retries controlados),
-
más escalable (workers horizontales),
-
más ordenado (tareas idempotentes, pipelines),
-
y más observable (qué se procesó, qué falló, qué quedó pendiente).
Cierre: una arquitectura no es un diagrama, es una promesa operativa
Vista así, la arquitectura deja de ser “tecnología usada” y se vuelve “problemas evitados”.
-
Edge (SQLite): que el dato exista aunque el mundo falle.
-
Cálculo local (Redis): que 15-min sea confiable y rápido, no un castigo.
-
Cloud (MongoDB): que el histórico masivo no sea una deuda impagable.
-
Multi-sitio (MariaDB): que las sedes convivan sin caos.
-
Celery: que el sistema procese de verdad, sin ahogarse en la interfaz web.
Pregunta para abrir conversación:
En tu operación, ¿en qué “velocidad” se rompen más los datos: edge, cálculo local 15-min, cloud histórico, o multi-sitio?
